There is a new Tool for Thought on the horizon that goes by the name Tana, and there is a lot of buzz about it on Twitter and YouTube.
I am also very excited about Tana and wanted to write a few words of early impressions and, along the way, address some questions I have seen online.
First, I am not a Tana employee, nor do I receive any financial support from them. I have been a Tana alpha tester since early this year and sincerely believe in the product.
Early Access
The first thing to know is that the product is in development and, at the time of this writing, it is in “early access” which means it’s further along than an alpha version of an app but not really a full beta yet. This means things are missing from the tool.
However, what it can do already at this point is very promising. If you are interested in giving Tana a try, sign up for early access at their site: https://tana.inc/
Let me tell you what I like about Tana.
Outliner-based note-taking & database
I am not sure the good crew at Tana would explain Tana this way, but this is how I view Tana:
Tana is an outliner based note-taking app with a database built into it. It is for Personal Knowledge Management (PKM) and also collaborative knowledge management for teams and companies. Kitchen sink included!
It sounds so simple that most will be like: What? Why is that so special? How is it different than other tools?
It is different, it is a marriage of just the right elements that will set a new bar for other Tools for Thought.
I must tell you, this is the app I have dreamed of for years: The marriage of a free-form text environment with the power of structured data(a database). Tana delivers!
But…. back to my early impressions. To start, I need to explain these components: outliner and databases.
Tana is an Outliner
First, I am a long-time user of outliners. Outliners are unique writing tools that help you to organize your thoughts in a structured way with ease. This is accomplished by creating a bulleted list of thoughts and then using indentation (hierarchy) to group related thoughts.
Outliners are the thought scalpel of the modern-day thinker
For example, in the following screenshot, I have my notes on “cognitive distortions.” There are many of them, so I create one bullet as a top-level description, then I include notes under that top-level bullet to take further notes on that topic.

Tana outliner
You can also see that some of the cognitive distortions listed show no additional notes, but I promise you, they are there. The reason is that those notes are not visible is that they are “collapsed” or hidden away. This allows me to focus my attention on the ideas that I am working with and to tuck away conveniently the other ideas. But they are easily opened by toggling the display of their contents.
Outliners are the thought scalpel of the modern-day thinker. While they don’t click with everyone, for me, they are a very powerful thinking tool, and I couldn’t imagine living without them.
As a side note, I also use Obsidian heavily. Obsidian is not an outliner, but is still a brilliant writing tool. Obsidian is well suited for long-form writing.
However, I don’t want to get bogged down into discussing outliners right now, as Tana is much more than an outliner.
Let’s just say the outliner editor is one of its strengths.
Supertags
Tana has a superpower, it is called supertags. They don’t seem all that special at first, but once you start working with them, you realize that you have entered into a new realm of productivity.
What is a supertag? It is best to understand supertags at two levels of use:
- Level 1: a supertag behaves like a tag as we would use in any other tool. Tags are labels that identify the type of thought or idea they are “tagged” to. So, for example, you make a note about your mother’s apple pie recipe, and you tag it with #recipe. Later you make a note of your friend’s fudge cookie recipe, and you tag it #recipe. By tagging these as recipes, you identify what they are, and often it makes it easier to find all your recipes hidden away in your archive of notes at a later time. Tags are a common feature in most programs today.
- Level 2: In addition to traditional tag support as described, Tana goes to another level in allowing a tag to have additional data elements.
Take a look at this next screenshot from Tana to begin to understand what a supertag is:
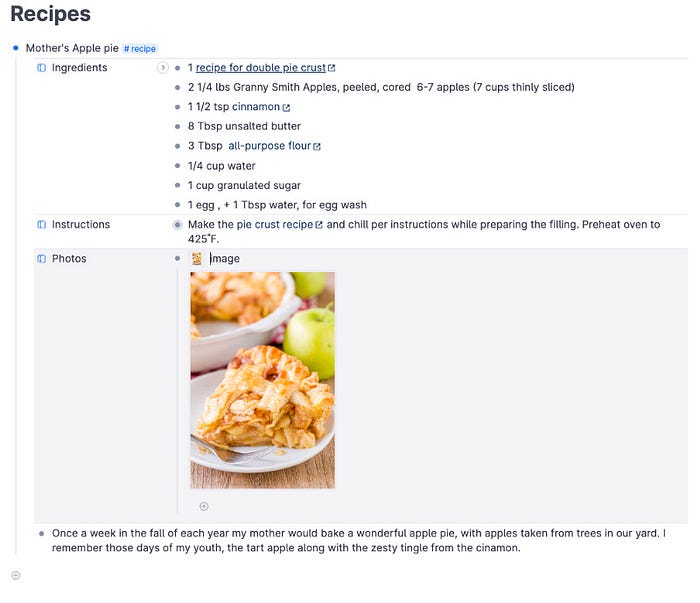
A node with #recipe supertag applied to it and showing all the fields connected with that recipe.
Here I started a note on my mother’s apple pie recipe and tagged it as #recipe. However, as you see, there are places for information about the recipe’s ingredients, cooking instructions, and photos.
Tana allows us to “attach” additional data points we want to collect for supertags. In other environments, these kinds of data elements might be referred to as metadata or fields or cells or frontmatter (YAML), or schema.
Tana uses the word field to define these additional data elements to add structured data elements to a supertag.
Here is what this looks like in Tana to define the fields of a supertag:

Defining the fields of a supertag called #recipe.
In Tana, I define the name of the supertag, give it a description, and then define the content, that is, the additional fields or data elements I want to capture when I use the #recipe supertag.
Tana supports multiple data types, such as dates, numbers, URLs, and lookup fields.
For any of you that have experience with databases, you will now realize that supertags give us the power of a database in our notes.
Read again: the powers of a database in our notes.
While the word database might sound complex to some, it isn’t. Looking at the recipe example, we all know that a recipe has ingredients and cooking instructions. These are the typical things you would collect into your notes.
So the database concept is not a scary thing, just an extension of something we already know and frequently do in our notes: categorizing thoughts into their discrete elements.
Now let me digress briefly for those nerds amongst us. For those who like working with databases, you will be amazed at what Tana can do. (Slipping into geek mode for a moment… please forgive me).
- — — Start NERD mode — — -
Tana supertags support many common data modeling concepts, though they are not restrictive. Since this is a note-taking tool, supertags give the user a lot of freedom to structure their data and not many constraints.
Supertags support the concepts of inheritance and merging.
Inheritance
With inheritance, you can define a supertag and have it based on another supertag. That is to say, one supertag can inherit all the fields of another supertag and still have its own unique fields.
For example, let’s say you define a #person supertag with the fields: Name, Address, Email, and Phone number. Now you want to create a supertag called #employee. That supertag also needs all the same data elements as #person but with additional data elements. Supertags solve this problem.
Upon further reflection, having looked at the #employee supertag, I think it would be useful to add an Employer field to #employee. I would configure the Employer field to initialize its value to our company name as its default value.
Going further, a supertag can be based on another supertag that is also based on another supertag. Did I lose you there? let me demonstrate what I mean.
In my workspace, I have the following supertags defined:
#person
Then #person supertag serves as a base tag for other tags:
#person → #friend
#person →#customer
#person → #employee
Then #employee, which is based on #person, is used as the basis for other supertags, and so on and so on and so on (you get the idea).
#person → #employee → #directReport
#person → #employee → #management → #executiveTeam
These supertags build on one another, providing me with consistent ways of collecting information. Each time a supertag inherits a supertag, it gets all the fields and settings of that “parent” supertag.
Merging
Regarding merging, supertags can be combined on one node. Imagine I am doing a personnel review. I may need to use the #employee supertag and #yearlyEmployeReview supertag together. They work independently of one another, but they can be used together, and all the data elements of these supertags can be captured in one note. Here is a note with two supertags demonstrating how Tana merges them:
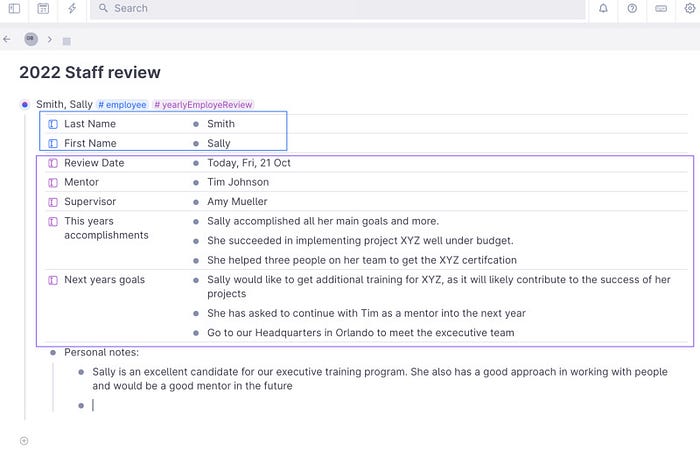
Two supertags on one node, thus merging their collective fields into that node.
- — — End NERD mode — — -
Querying your data
Another superpower of Tana is the ability to query your notes. Tana has several fast ways of generating queries based on supertags or the contents of your notes. It also has a query design tool:

Query designer in Tana, along with results output as a table.
In the upper half, I have defined what I want to query. In this case, I want to see employees but not if they have the #yearlyEmployeReview tag. Beneath the query, I see the results.
Also, the results are editable — this is not a read-only view. I can modify values as seen in the table or add new notes (or records), and they will be automatically “supertagged” with #employee.
The query tool provides many options, and I am still learning them. It is a lot of fun to discover new and interesting ways to query my notes.
These queries can also be displayed with other layouts, for example, as a list:

or as tabs:
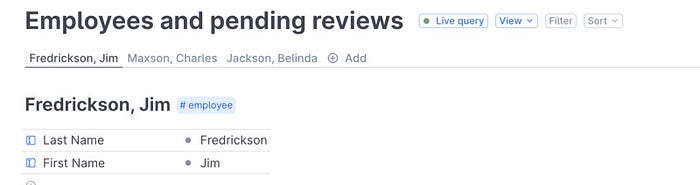
or as cards:
These layouts support filtering, grouping, and sorting. You can even create Kanban boards with these queries.
With Tana, you can create useful and attractive dashboards from your notes with surprisingly little effort.
Importing Data into Tana
For those already using Tools for Thought, the question is how to migrate your existing notes into Tana.
The good news is that Tana can import data from other note-taking tools, including Roam, Workflowy, Logseq, Obsidian, and more import formats to come.
Take for example Obsidian, since Obsidian is based on markdown files, the import should be straightforward. I recently imported my Obsidian vault and was very satisfied with the results.
Of course, there is not a 100% mapping of Obsidian functionality to Tana, so some things still need “massaging” after the import. Even though this takes some additional time, I find it a good time to review my notes and see if they can be structured better way to leverage Tana functionality.
Therefore, use the importer tools to get your data in, but plan to take the time to process your data afterward. The time is well spent!
Exporting Data out of Tana
Today, you can already export your data from Tana in JSON format. What impresses me about the export is it is a full-fidelity export of data related to your graph. This means that you can export all of your data into this format. This is an excellent start!
However, this format is useful to programmers but not so much for the rest of us. Tana plans to have several export options available soon. I expect the ability to export to Markdown as an option soon.
Additionally, Tana has taken an interesting approach to import and export.
For their importing, they have an open-sourced tool and open-sourced file format for importing data into Tana. This means that any company can, with reasonable ease, create a tool for importing their data into Tana.
In fact, I have a test database that I frequently use for importing into Tools for Thought to test them out. I used the Tana Import Format, and it was super easy to import my data. In fact, it has never been easier for me when I compare all the previous tests I have done with the tools.
So the open-sourced tool and file format is a smart move on the part of the Tana team, one that I expect to see their competitors copy in the future.
You can check out the open-source codebase on GitHub at this link: https://github.com/tana-team/tana-importer
What is missing?
As mentioned, Tana is in early access. The product has an amazing foundation, but we are waiting for a few key features.
Mobile
Tana works in a mobile browser, but like most outliners, it’s not a great experience in a mobile scenario. I do know that the Tana team, already from early on in their development work, have been prototyping and experimenting with mobile. So the good news is that we will eventually have a good mobile app for Tana.
Offline
Tana currently requires a live internet connection. Again, at some point in the not-so-distant future, I know it is planned that Tana will function offline. For some people, this is a big deal. For me, I don’t think in the last few years I have had a device that isn’t always connected to the internet, so this is not something I worry about. But ok, this will be nice to have.
Markdown
As mentioned in the previous section, we can’t yet export Tana data to markdown. However, for some users, data storage in markdown is a key requirement. I think I can reasonably conclude and say that Tana will never store its data in markdown. Tana is a graph database, and this is impractical to store the native graph data in markdown. However, exporting it into usable markdown files will be possible.
Programmability (API)
Currently, no API on the client or server has been made publicly available. But I know firsthand this is being worked on. Again it’s just a matter of time until we have this feature.
One interesting thing about Tana, its core feature set eliminates many of the hacks we made in the past for other tools.
For example, if you are a user of my Roam42 plugin for Roam Research, which included SmartBlocks, workBench, privacy mode, exporter tools, onboarding help, and a bunch of other tools, almost all the Roam42 features are in some form or fashion built into Tana.
This is a good thing! Fewer plugins is what is needed in order to make Tools for Thought more accessible to a broader audience.
Frankly, users do not enjoy reading complex plugin instructions or fiddling with Javascript to get things like natural language processing for handling dates in their editor. This kind of stuff should just be built into the tools, and Tana has it.
Who is Tana for?
Oh, this is a question I have been pondering now for months. I have no simple answer to this question. Tana will be very useful to those who like outliners and who believe in the power of having a database built into their notes.
Tana is well suited for those doing PKM, researchers, writers, and those who need team collaboration.
By 2023 (my prediction), when we have a programming API, I can foresee many integrations with other systems through tools like Zapier and IFTTT. This will help us to connect Tana to the other tools we use in our everyday lives.
Tana is a well-thought-out product, and the team has a good vision of where they want Tana to go.
So to wrap this up, I encourage you to sign up for early access and try Tana.
Thank you for reading this article. Please check out more of my work at https://tfthacker.com